
Typhoon 1.5
Collection
06-2024 Text ThaiLLM release developed by SCB 10X. • 6 items • Updated
Typhoon-1.5-72B-instruct: Thai Large Language Model (Instruct)
Typhoon-1.5-72B-instruct is a instruct Thai 🇹🇭 large language model with 72 billion parameters, and it is based on Qwen1.5-72B.
We also have a newer release of 1.5x 70B, which is better for application use cases. here
For release post, please see our blog.
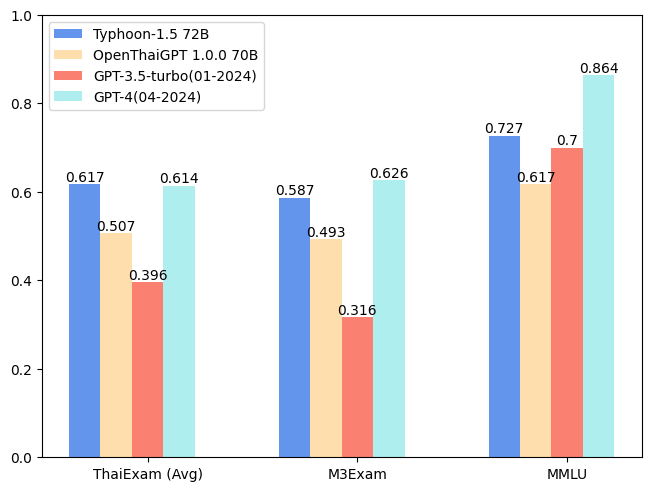
| Model | ONET | IC | TGAT | TPAT-1 | A-Level | Average (ThaiExam) | M3Exam | MMLU |
|---|---|---|---|---|---|---|---|---|
| Typhoon-1.5 72B | 0.562 | 0.716 | 0.778 | 0.5 | 0.528 | 0.6168 | 0.587 | 0.7271 |
| OpenThaiGPT 1.0.0 70B | 0.447 | 0.492 | 0.778 | 0.5 | 0.319 | 0.5072 | 0.493 | 0.6167 |
| GPT-3.5-turbo(01-2024) | 0.358 | 0.279 | 0.678 | 0.345 | 0.318 | 0.3956 | 0.316 | 0.700** |
| GPT-4(04-2024) | 0.589 | 0.594 | 0.756 | 0.517 | 0.616 | 0.6144 | 0.626 | 0.864** |
| ** We report the MMLU score that is reported in GPT-4 Tech Report. |
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/typhoon-v1.5-72b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
) # We do not recommend loading the model using 4-bit and 8-bit BNB as it may produce inaccurate results.
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=1024,
do_sample=True,
temperature=0.6,
top_p=0.9,
repetition_penalty=1.15
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
We use chatml chat-template.
{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|im_end|>' + '\n'}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != 'assistant' %}{{ '<|im_start|>assistant\n' }}{% endif %}
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
https://twitter.com/opentyphoon
@article{pipatanakul2023typhoon,
title={Typhoon: Thai Large Language Models},
author={Kunat Pipatanakul and Phatrasek Jirabovonvisut and Potsawee Manakul and Sittipong Sripaisarnmongkol and Ruangsak Patomwong and Pathomporn Chokchainant and Kasima Tharnpipitchai},
year={2023},
journal={arXiv preprint arXiv:2312.13951},
url={https://arxiv.org/abs/2312.13951}
}