
datasets:
- AnasAlokla/multilingual_go_emotions
language:
- ar
- en
- fr
- es
- nl
- tr
library_name: transformers
tags:
- emotion
- classification
- text-classification
- bert
- emojis
- emotions
- v1.0
- sentiment-analysis
- nlp
- chatbot
- social-media
- mental-health
- short-text
- emotion-detection
- transformers
- expressive
- ai
- machine-learning
- inference
- edge-ai
- smart-replies
- tone-analysis
metrics:
- accuracy
- f1
- recall
base_model:
- google-bert/bert-base-multilingual-cased
pipeline_tag: text-classification
🌍 Multilingual GoEmotions Classifier 💬
Table of Contents
- 📖 Overview
- ✨ Key Features
- 💫 Supported Emotions
- 🔗 Links
- ⚙️ Installation
- 🚀 Quickstart: Emotion Detection
- 📊 Evaluation
- 💡 Use Cases
- 📚 Trained On
- 🔧 Fine-Tuning Guide
- 🏷️ Tags
- 💬 Support & Contact
Overview
This repository contains a powerful multilingual, multi-label emotion classification model. It is fine-tuned from the robust bert-base-multilingual-cased model on the comprehensive multilingual_go_emotions dataset. The model is designed to analyze text and identify a wide spectrum of 27 different emotions, plus a neutral category. Its ability to detect multiple emotions simultaneously makes it highly effective for understanding nuanced text from diverse sources.
- Model Name: AnasAlokla/multilingual_go_emotions
- Architecture: BERT (bert-base-multilingual-cased)
- Task: Multi-Label Text Classification
- Languages: Arabic, English, French, Spanish, Dutch, Turkish
Key Features
- 🌍 Truly Multilingual: Natively supports 6 major languages, making it ideal for global applications.
- 🏷️ Multi-Label Classification: Capable of detecting multiple emotions in a single piece of text, capturing complex emotional expressions.
- 💪 High Performance: Built on
bert-base-multilingual-cased, delivering strong results across all supported languages and emotions. See the detailed evaluation metrics. - 🔗 Open & Accessible: Comes with a live demo, the full dataset, and the complete training code for full transparency and reproducibility.
- V1.1 Improved Version: An updated model is available that specifically improves performance on low-frequency emotion samples.
Supported Emotions
The model is trained to classify text into 27 distinct emotion categories as well as a neutral class:
| Emotion | Emoji | Emotion | Emoji |
|---|---|---|---|
| Admiration | 🤩 | Love | ❤️ |
| Amusement | 😄 | Nervousness | 😰 |
| Anger | 😠 | Optimism | ✨ |
| Annoyance | 🙄 | Pride | 👑 |
| Approval | 👍 | Realization | 💡 |
| Caring | 🤗 | Relief | 😌 |
| Confusion | 😕 | Remorse | 😔 |
| Curiosity | 🤔 | Sadness | 😢 |
| Desire | 🔥 | Surprise | 😲 |
| Disappointment | 😞 | Disapproval | 👎 |
| Disgust | 🤢 | Gratitude | 🙏 |
| Embarrassment | 😳 | Grief | 😭 |
| Excitement | 🎉 | Joy | 😊 |
| Fear | 😱 | Neutral | 😐 |
Links
- Live Demo: Hugging Face Space
- Dataset (Supports 6 Languages): multilingual_go_emotions
- Model Used: AnasAlokla/multilingual_go_emotions
- GitHub Code: emotion_chatbot
- Improved Version (V1.1): multilingual_go_emotions_V1.1
- Improved Version (V1.2): multilingual_go_emotions_V1.2
Installation
Install the required libraries using pip:
pip install transformers torch
Quickstart: Emotion Detection
You can easily use this model for multi-label emotion classification with the transformers pipeline. Set top_k=None to see all predicted emotions above the model's default threshold.
from transformers import pipeline
# Load the multilingual, multi-label emotion classification pipeline
emotion_classifier = pipeline(
"text-classification",
model="AnasAlokla/multilingual_go_emotions",
top_k=None # To return all scores for each label
)
# --- Example 1: English ---
text_en = "I'm so happy for you, but I'm also a little bit sad to see you go."
results_en = emotion_classifier(text_en)
print(f"Text (EN): {text_en}")
print(f"Predictions: {results_en}\n")
# --- Example 2: Spanish ---
text_es = "¡Qué sorpresa! No me lo esperaba para nada."
results_es = emotion_classifier(text_es)
print(f"Text (ES): {text_es}")
print(f"Predictions: {results_es}\n")
# --- Example 3: Arabic ---
text_ar = "أشعر بخيبة أمل وغضب بسبب ما حدث"
results_ar = emotion_classifier(text_ar)
print(f"Text (AR): {text_ar}")
print(f"Predictions: {results_ar}")
Expected Output (structure):
Text (EN): I'm so happy for you, but I'm also a little bit sad to see you go. Predictions: [[{'label': 'joy', 'score': 0.9...}, {'label': 'sadness', 'score': 0.8...}, {'label': 'caring', 'score': 0.5...}, ...]]
Text (ES): ¡Qué sorpresa! No me lo esperaba para nada. Predictions: [[{'label': 'surprise', 'score': 0.9...}, {'label': 'excitement', 'score': 0.4...}, ...]]
Text (AR): أشعر بخيبة أمل وغضب بسبب ما حدث Predictions: [[{'label': 'disappointment', 'score': 0.9...}, {'label': 'anger', 'score': 0.9...}, ...]]
Evaluation
The model's performance was rigorously evaluated on the test set.
Test Set Performance
The following table shows the performance metrics of the fine-tuned model on the test set, broken down by emotion category.
| index | accuracy | precision | recall | f1 | mcc | support | threshold |
|---|---|---|---|---|---|---|---|
| admiration | 0.942 | 0.652 | 0.684 | 0.667 | 0.636 | 2790 | 0.4 |
| amusement | 0.973 | 0.735 | 0.817 | 0.774 | 0.76 | 1866 | 0.35 |
| anger | 0.96 | 0.411 | 0.364 | 0.386 | 0.366 | 1128 | 0.35 |
| annoyance | 0.896 | 0.246 | 0.481 | 0.325 | 0.293 | 1704 | 0.15 |
| approval | 0.91 | 0.329 | 0.383 | 0.354 | 0.307 | 2094 | 0.2 |
| caring | 0.958 | 0.285 | 0.46 | 0.352 | 0.341 | 816 | 0.15 |
| confusion | 0.965 | 0.444 | 0.401 | 0.421 | 0.404 | 1020 | 0.25 |
| curiosity | 0.935 | 0.433 | 0.74 | 0.546 | 0.535 | 1734 | 0.25 |
| desire | 0.984 | 0.404 | 0.534 | 0.46 | 0.457 | 414 | 0.25 |
| disappointment | 0.942 | 0.224 | 0.345 | 0.272 | 0.249 | 1014 | 0.15 |
| disapproval | 0.935 | 0.306 | 0.413 | 0.352 | 0.322 | 1398 | 0.25 |
| disgust | 0.975 | 0.343 | 0.418 | 0.377 | 0.366 | 600 | 0.15 |
| embarrassment | 0.99 | 0.28 | 0.242 | 0.26 | 0.255 | 240 | 0.1 |
| excitement | 0.973 | 0.344 | 0.425 | 0.38 | 0.369 | 624 | 0.15 |
| fear | 0.987 | 0.599 | 0.522 | 0.558 | 0.553 | 498 | 0.35 |
| gratitude | 0.989 | 0.924 | 0.902 | 0.913 | 0.907 | 2004 | 0.4 |
| grief | 0.999 | 0 | 0 | 0 | 0 | 36 | 0.05 |
| joy | 0.965 | 0.454 | 0.532 | 0.49 | 0.474 | 1032 | 0.25 |
| love | 0.973 | 0.731 | 0.829 | 0.777 | 0.765 | 1812 | 0.35 |
| nervousness | 0.996 | 0.385 | 0.25 | 0.303 | 0.308 | 120 | 0.1 |
| optimism | 0.973 | 0.588 | 0.525 | 0.555 | 0.542 | 1062 | 0.25 |
| pride | 0.997 | 0 | 0 | 0 | 0 | 84 | 0.05 |
| realization | 0.962 | 0.202 | 0.189 | 0.195 | 0.176 | 792 | 0.15 |
| relief | 0.996 | 0 | 0 | 0 | 0 | 138 | 0.05 |
| remorse | 0.988 | 0.597 | 0.808 | 0.687 | 0.689 | 516 | 0.15 |
| sadness | 0.97 | 0.548 | 0.434 | 0.484 | 0.473 | 1062 | 0.4 |
| surprise | 0.974 | 0.487 | 0.569 | 0.524 | 0.513 | 828 | 0.3 |
| neutral | 0.726 | 0.551 | 0.818 | 0.658 | 0.468 | 10524 | 0.2 |
Use Cases
This model is ideal for applications requiring nuanced emotional understanding across different languages:
Global Customer Feedback Analysis: Analyze customer reviews, support tickets, and survey responses from around the world to gauge sentiment.
Multilingual Social Media Monitoring: Track brand perception and public mood across different regions and languages.
Advanced Chatbot Development: Build more empathetic and responsive chatbots that can understand user emotions in their native language.
Content Moderation: Automatically flag toxic, aggressive, or sensitive content on international platforms.
Market Research: Gain insights into how different cultures express emotions in text.
Trained On
Base Model: google-bert/bert-base-multilingual-cased - A powerful pretrained model supporting 104 languages.
Dataset: multilingual_go_emotions - A carefully translated and curated dataset for multilingual emotion analysis, based on the original Google GoEmotions dataset.
Fine-Tuning Guide
To adapt this model for your own dataset or to replicate the training process, you can follow the methodology outlined in the official code repository. The repository provides a complete, end-to-end example, including data preprocessing, training scripts, and evaluation logic.
For full details, please refer to the GitHub repository: emotion_chatbot
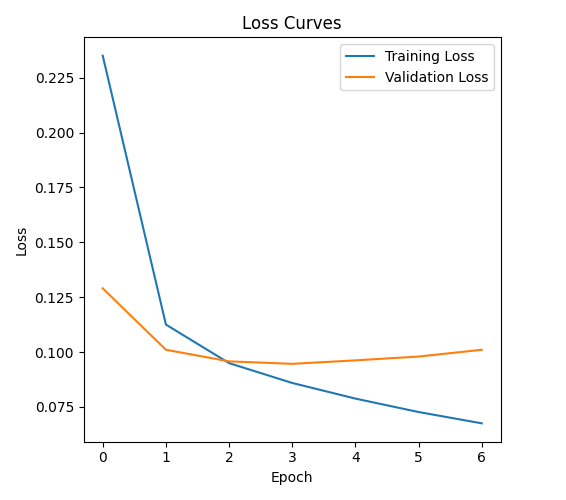
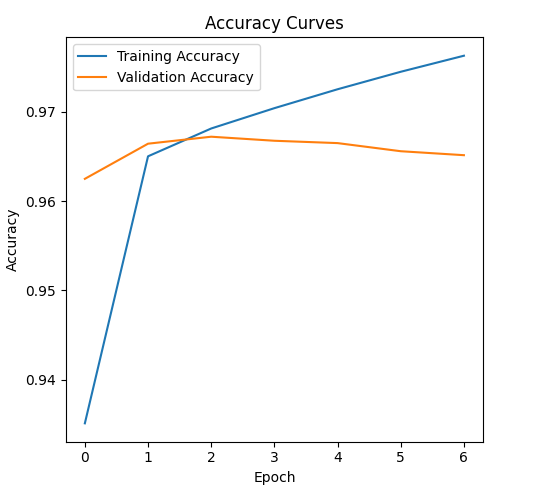
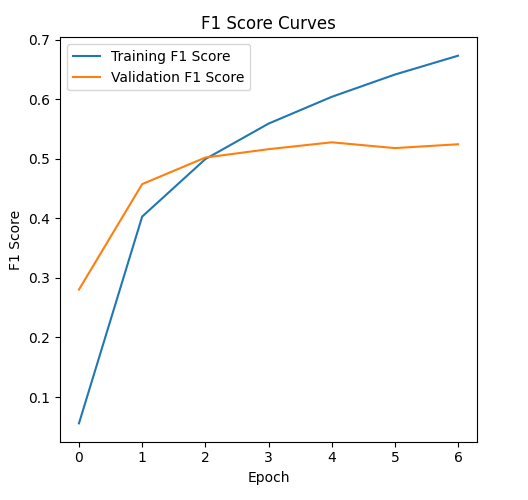
The following plots visualize the model's performance during the fine-tuning process across epochs.
Loss Curves (Training vs. Validation)
Accuracy Curves (Training vs. Validation)
F1 Score Curves (Training vs. Validation)
Tags
#multilingual-nlp #emotion-classification #text-classification #multi-label #bert
#transformer #natural-language-processing #sentiment-analysis #deep-learning
#arabic-nlp #french-nlp #spanish-nlp #goemotions
#BERT-Emotion #edge-nlp #emotion-detection #offline-nlp#sentiment-analysis #emojis #emotions #embedded-nlp
#ai-for-iot #efficient-bert #nlp2025 #context-aware #edge-ml#smart-home-ai #emotion-aware #voice-ai #eco-ai #chatbot #social-media#mental-health #short-text #smart-replies #tone-analysis
Support & Contact
For questions, bug reports, or collaboration inquiries, please open an issue on the Hugging Face Hub repository or contact the author directly.
Author: Anas Hamid Alokla
📬 Email: [email protected]