
Voxtral Realtime
Paper
• 2602.11298 • Published
• 18
Voxtral Mini 4B Realtime 2602 is a multilingual, realtime speech-transcription model and among the first open-source solutions to achieve accuracy comparable to offline systems with a delay of <500ms. It supports 13 languages and outperforms existing open-source baselines across a range of tasks, making it ideal for applications like voice assistants and live subtitling.
Built with a natively streaming architecture and a custom causal audio encoder - it allows configurable transcription delays (240ms to 2.4s), enabling users to balance latency and accuracy based on their needs. At a 480ms delay, it matches the performance of leading offline open-source transcription models, as well as realtime APIs.
As a 4B-parameter model, is optimized for on-device deployment, requiring minimal hardware resources. It runs in realtime with on devices minimal hardware with throughput exceeding 12.5 tokens/second.
This model is released in BF16 under the Apache-2 license, ensuring flexibility for both research and commercial use.
For more details, see our:
Voxtral Mini 4B Realtime consists of two main architectural components:
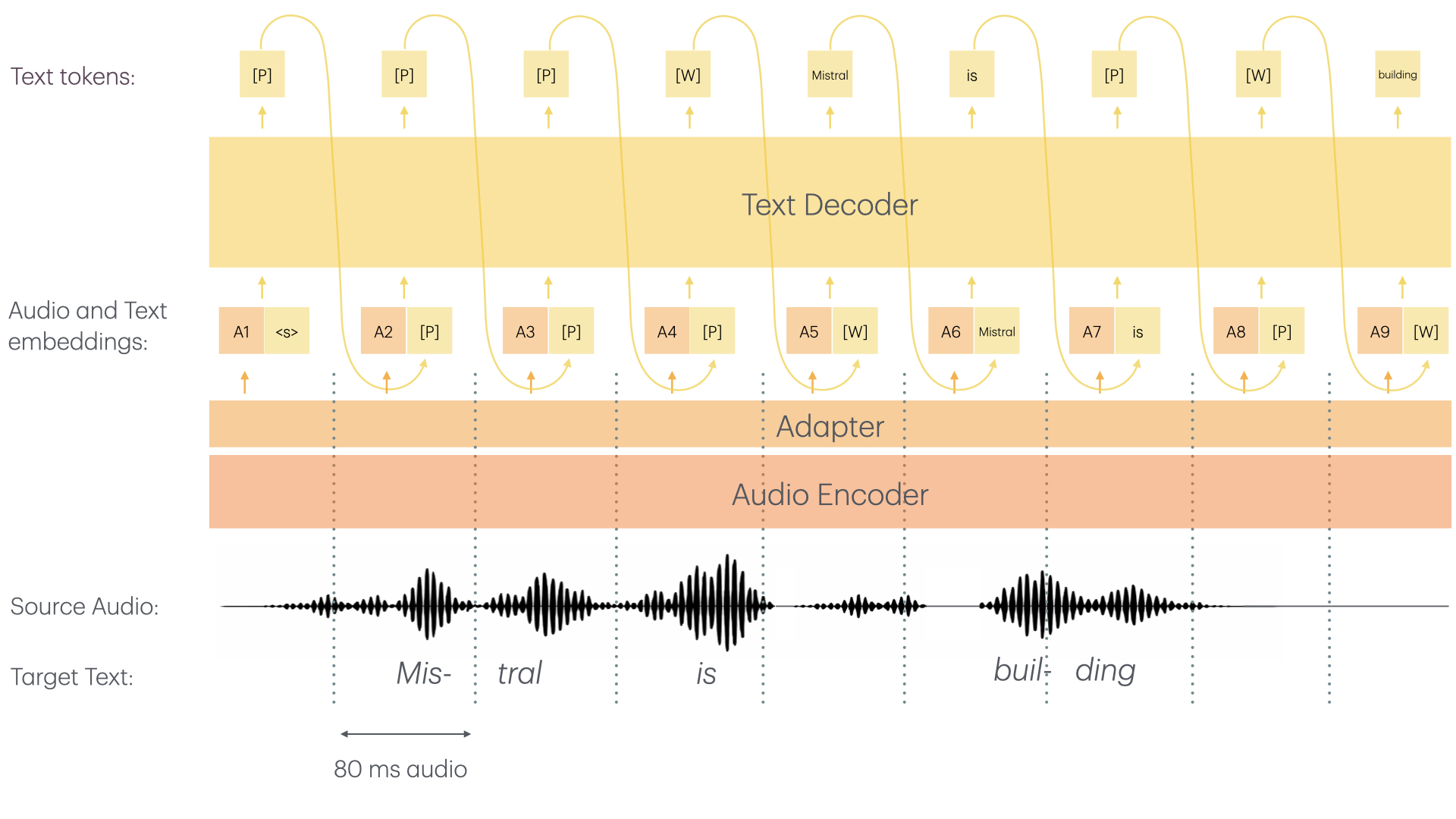
The Voxtral Mini 4B Realtime model offers the following capabilities:
Real-Time Transcription Purposes:
Bringing real-time transcription capabilities to all.
We recommend deploying with the following best practices:
--max-model-len accordingly. To live-record a 1h meeting, you need to set --max-model-len >= 3600 / 0.8 = 45000.
In theory, you should be able to record with no limit; in practice, pre-allocations of RoPE parameters among other things limits --max-model-len.
For the best user experience, we recommend to simply instantiate vLLM with the default parameters which will automatically set a maximum model length of 131072 (~ca. 3h)."transcription_delay_ms": 480 parameter
in the tekken.json file to any multiple of 80ms between 80 and 1200, as well as 2400 as a standalone value.We compare Voxtral Mini 4B Realtime to similar models - both offline models and realtime. Voxtral Mini 4B Realtime is competitive to leading offline models and shows significant gains over existing open-source realtime solutions.
| Model | Delay | AVG | Arabic | German | English | Spanish | French | Hindi | Italian | Dutch | Portuguese | Chinese | Japanese | Korean | Russian |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voxtral Mini Transcribe 2.0 | Offline | 5.90% | 13.54% | 3.54% | 3.32% | 2.63% | 4.32% | 10.33% | 2.17% | 4.78% | 3.56% | 7.30% | 4.14% | 12.29% | 4.75% |
| Voxtral Mini 4B Realtime 2602 | 480 ms | 8.72% | 22.53% | 6.19% | 4.90% | 3.31% | 6.42% | 12.88% | 3.27% | 7.07% | 5.03% | 10.45% | 9.59% | 15.74% | 6.02% |
| 160 ms | 12.60% | 24.33% | 9.50% | 6.46% | 5.34% | 9.75% | 15.28% | 5.59% | 11.39% | 10.01% | 17.67% | 19.17% | 19.81% | 9.53% | |
| 240 ms | 10.80% | 23.95% | 8.15% | 5.91% | 4.59% | 8.00% | 14.26% | 4.41% | 9.23% | 7.51% | 13.84% | 15.17% | 17.56% | 7.87% | |
| 960 ms | 7.70% | 20.32% | 4.87% | 4.34% | 2.98% | 5.68% | 11.82% | 2.46% | 6.76% | 4.57% | 8.99% | 6.80% | 14.90% | 5.56% | |
| 2400 ms | 6.73% | 14.71% | 4.15% | 4.05% | 2.71% | 5.23% | 10.73% | 2.37% | 5.91% | 3.93% | 8.48% | 5.50% | 14.30% | 5.41% |
| Model | Delay | Meanwhile (<10m) | E-21 (<10m) | E-22 (<10m) | TEDLIUM (<20m) |
|---|---|---|---|---|---|
| Voxtral Mini Transcribe 2.0 | Offline | 4.08% | 9.81% | 11.69% | 2.86% |
| Voxtral Mini 4B Realtime 2602 | 480ms | 5.05% | 10.23% | 12.30% | 3.17% |
| Model | Delay | CHiME-4 | GigaSpeech 2k Subset | AMI IHM | SwitchBoard | CHiME-4 SP | GISpeech 2k Subset |
|---|---|---|---|---|---|---|---|
| Voxtral Mini Transcribe 2.0 | Offline | 10.39% | 6.81% | 14.43% | 11.54% | 10.42% | 1.74% |
| Voxtral Mini 4B Realtime 2602 | 480ms | 10.50% | 7.35% | 15.05% | 11.65% | 12.41% | 1.73% |
This model is licensed under the Apache 2.0 License.
You must not use this model in a manner that infringes, misappropriates, or otherwise violates any third party’s rights, including intellectual property rights.
Base model
mistralai/Ministral-3-3B-Base-2512